

1. 引言
随着智能交通系统的发展,车辆轨迹数据的规模呈指数级增长。如何从海量的 GPS 点位中提取有效信息,例如城市热点区域、居民出行规律等,成为交通规划与智慧城市研究的重要课题。
K-Means 是一种经典且高效的聚类算法,尤其适合对大规模数据进行探索性分析。本文将利用某行程的起点经纬度数据(约 240 万条记录),通过 K-Means 聚类识别城市中的主要交通热点。为了处理大规模数据,我们采用 Mini-Batch K-Means 算法,并通过肘部法则自动确定最佳聚类数。最后,结合 Folium 地图库将聚类结果在地图上直观呈现。
2. K-Means 算法原理回顾
2.1 基本思想
K-Means 的目标是将 n 个样本划分到 K 个簇中,使得每个样本属于距离其最近的簇中心(均值),并最小化簇内样本到簇中心的距离平方和(Inertia,即 SSE)。
2.2 算法步骤
初始化:随机选择 K 个样本作为初始聚类中心。
分配样本:计算每个样本到各聚类中心的距离,将其分配到距离最近的簇。
更新中心:对每个簇,重新计算其中心(所有样本的均值)。
迭代:重复步骤 2 和 3,直到聚类中心不再变化或达到最大迭代次数。
2.3 优缺点
优点:算法简单、速度快,适合处理大规模数据。
缺点:需要预先指定 K 值;对初始中心敏感,可能陷入局部最优;对异常值敏感;假设簇为凸形且大小相似。
3. 大规模数据下的优化:Mini-Batch K-Means
面对百万级以上的数据集,传统 K-Means 每次迭代需要扫描全部样本,计算开销巨大。Mini-Batch K-Means 通过每次只使用一个小的随机样本子集(mini-batch)来更新聚类中心,从而大幅降低计算复杂度。
其核心思想是:
每次从数据集中随机抽取一个小批量(例如
batch_size=10000)。对该批量的样本分配到最近的簇。
使用分配结果对聚类中心进行增量更新(移动平均)。
这样既保证了算法的收敛性,又显著提升了训练速度。Scikit-learn 中提供了 MiniBatchKMeans 的实现,非常适合本案例的数据规模。
4. 实验流程
4.1 数据准备与预处理
原始数据为 CSV 格式,提取起点和终点的经纬度。我们仅使用起点经纬度作为聚类特征。
import pandas as pd
import numpy as np
coords = df[['start_lat', 'start_lon']].dropna().values
print("数据量:", len(coords)) # 输出: 24237534.2 坐标投影转换
经纬度属于地理坐标系(WGS84),计算欧氏距离时直接使用角度会产生严重失真。因此,需要将其投影到平面坐标系(如 Web Mercator,EPSG:3857),使得距离单位统一为米。
我们使用 pyproj 库进行坐标转换:
from pyproj import Transformer
transformer = Transformer.from_crs("EPSG:4326", "EPSG:3857")
X_proj = np.array([transformer.transform(lat, lon) for lat, lon in coords])转换后的 X_proj 是一个形状为 (2423753, 2) 的数组,单位为米,可直接用于 K-Means 聚类。
4.3 聚类数 K 的选择:肘部法则
为了确定合适的聚类数量,我们分别对 K=2 到 K=14 训练 Mini-Batch K-Means,并记录每个模型的 SSE(Inertia)。绘制 SSE 随 K 变化的曲线,寻找“肘部“位置。
from sklearn.cluster import MiniBatchKMeans
sse = []
k_range = range(2, 15)
for k in k_range:
kmeans = MiniBatchKMeans(n_clusters=k, batch_size=10000, random_state=42)
kmeans.fit(X_proj)
sse.append(kmeans.inertia_)绘制肘部曲线:
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 5))
plt.plot(list(k_range), sse, marker='o')
plt.xlabel('Number of Clusters (K)')
plt.ylabel('SSE')
plt.title('Elbow Method (GPS Data)')
plt.grid(True)
plt.show()肘部曲线图:
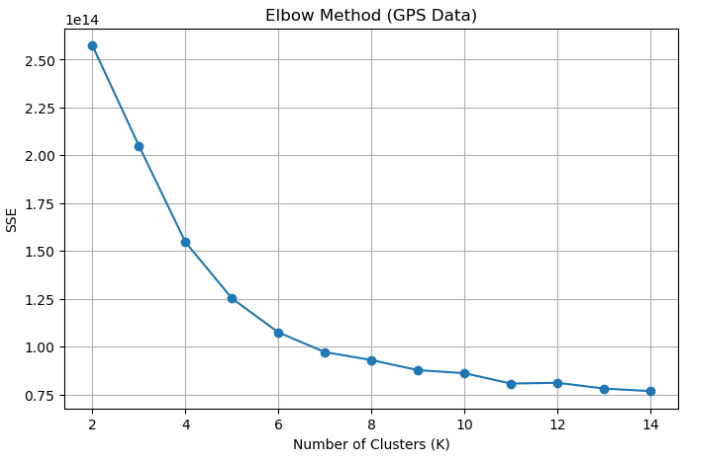
从图中可以看出,K=12 附近曲线下降幅度明显放缓,是一个合理的肘部位置。我们进一步通过计算二阶差分变化率来自动化选取最佳 K:
sse = np.array(sse)
diff = np.diff(sse)
ratio = diff[1:] / diff[:-1]
best_k = np.argmin(ratio) + 3 # +3 对应 k_range 的起点(2)
print("推荐 K =", best_k) # 输出: 124.4 执行最终聚类
确定 K=12 后,使用 Mini-Batch K-Means 对全部数据进行聚类。
final_kmeans = MiniBatchKMeans(n_clusters=12, batch_size=20000, random_state=42)
final_kmeans.fit(X_proj)
labels = final_kmeans.labels_4.5 聚类结果可视化
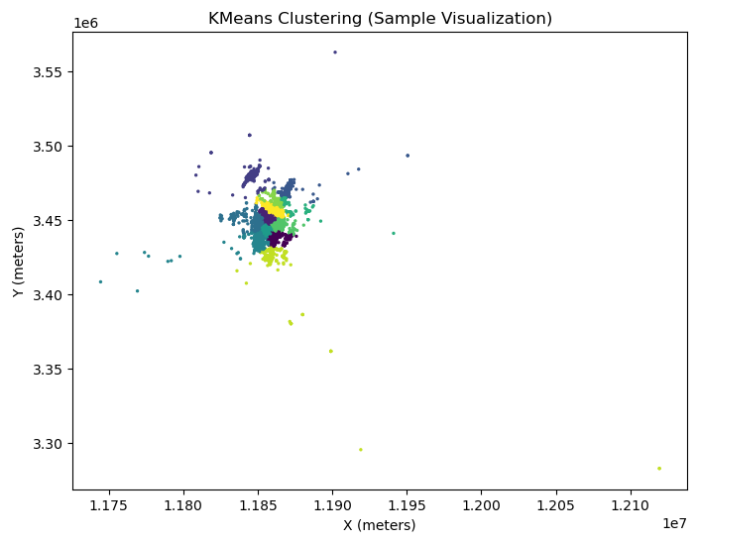
由于数据量巨大,直接绘制 240 万个点会导致图像过于密集且渲染缓慢。我们随机抽取 3 万个样本进行可视化。
sample_vis = 30000
idx = np.random.choice(len(X_proj), sample_vis, replace=False)
X_vis = X_proj[idx]
labels_vis = labels[idx]
plt.figure(figsize=(8, 6))
plt.scatter(X_vis[:, 0], X_vis[:, 1], c=labels_vis, s=2, cmap='tab20')
plt.title("K-Means Clustering (Sample Visualization)")
plt.xlabel("X (meters)")
plt.ylabel("Y (meters)")
plt.show()平面坐标聚类结果:
5. 与地图结合:地理可视化
将聚类中心从投影坐标反算回经纬度,并利用 Folium 库在 OpenStreetMap 底图上绘制聚类中心及样本分布。
5.1 聚类中心反算
transformer_inv = Transformer.from_crs("EPSG:3857", "EPSG:4326")
centers = final_kmeans.cluster_centers_
centers_latlon = [transformer_inv.transform(x, y)[::-1] for x, y in centers]5.2 生成交互式地图
使用 Folium 绘制散点图(MarkerCluster 或 CircleMarker),并标记聚类中心。
import folium
from folium.plugins import MarkerCluster
# 计算样本点经纬度(抽样)
sample_idx = np.random.choice(len(X_proj), 30000, replace=False)
sample_lonlat = [transformer_inv.transform(x, y)[::-1] for x, y in X_proj[sample_idx]]
# 创建地图
map_center = [29.563, 106.551] # 大致中心
m = folium.Map(location=map_center, zoom_start=11)
# 添加样本点(按簇着色)
for (lon, lat), label in zip(sample_lonlat, labels[sample_idx]):
folium.CircleMarker(
location=[lat, lon],
radius=2,
color=cluster_colors[label],
fill=True,
fill_opacity=0.3
).add_to(m)
# 添加聚类中心(红色星形标记)
for lon, lat in centers_latlon:
folium.Marker(
location=[lat, lon],
icon=folium.Icon(color='red', icon='star', prefix='fa')
).add_to(m)
m.save('clusters.html')最终生成的可视化地图如下图所示:
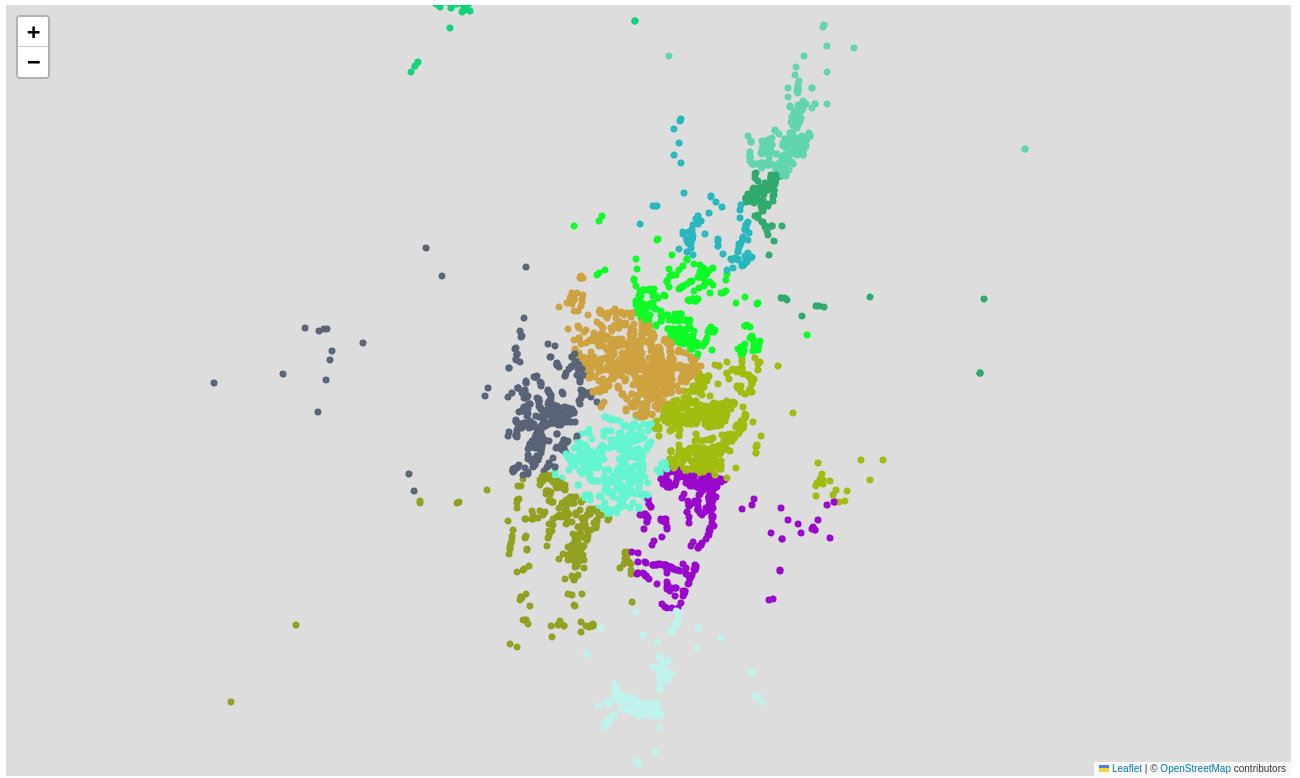
提示:在实际地图中,可以通过缩放和平移交互观察每个簇的具体地理位置,直观识别交通热点。
另外可以结合获取 GeoJSON 边界
阿里云 DataV
高德开放平台
Natural Earth(简化版)
import folium
import json
# 创建地图
m = folium.Map(location=center, zoom_start=10, tiles='CartoDB positron')
# 加载
with open('xxxx.geojson', 'r', encoding='utf-8') as f:
geojson_data = json.load(f)
folium.GeoJson(
geojson_data,
name='Boundary',
style_function=lambda x: {
'fillColor': 'none',
'color': 'black',
'weight': 2
}
).add_to(m)
# 添加聚类点(示例)
for (lon, lat), lab in zip(lon_lat, labels_vis):
folium.CircleMarker(
location=[lat, lon],
radius=2,
color=colors[lab],
fill=True
).add_to(m)
m6. 总结
本文通过一个完整的实战案例,演示了如何使用 K-Means 聚类处理大规模地理空间数据。主要技术要点包括:
坐标投影:将经纬度转换为平面坐标系,确保距离计算的准确性。
Mini-Batch K-Means:解决传统算法在大数据量下的性能瓶颈。
肘部法则:辅助确定最佳聚类数,提高模型的解释性。
地图可视化:将聚类结果与地理信息结合,赋予数据直观的空间含义。
希望本文能帮助读者掌握大规模轨迹数据聚类的基本方法,并激发更多时空数据挖掘的灵感。